
什麼是 Apache Kafka
Apache Kafka 是一個開源的分散式事件流(event streaming)平台,以提供持久性、高可擴展性、高吞吐量的同時維持低延遲為目標,能夠處理持續湧入的串流資料,並且依序逐步處理。
為何使用 Kafka
Apache Kafka 是針對處理大規模事件流而設計,每秒鐘可處理幾十萬條訊息。它採用了分散式架構,除了方便水平擴張,提供高可靠性與擴展性,還能將資料存放於硬碟,用於長時間地保存資料。
什麼是事件流(event streaming)?
就像人體中樞神經系統的數位化。從技術上來說,事件流是從資料(事件)的來源(如資料庫、感應器、移動裝置、雲服務和軟體應用程式等)即時捕捉數據的實踐。並以事件流的形式儲存數據,以便日後檢索、即時操作或處理。
以下是幾個事件流的應用實例:
- 連續分析網頁應用程式所產生的紀錄檔、追蹤網頁活動
- 持續擷取和分析物聯網(IoT)設備的感測器數據
- 即時處理支付和金融交易,例如在證券交易所、銀行和保險業
- 作為資料平台、事件驅動架構和微服務的基礎
Kafka 的優點
根據官網介紹,Kafka 提供了三個主要功能:
- 發布(寫入)和訂閱(讀取)事件流,包括從其他系統持續匯入/匯出資料
- 根據需求可持久儲存事件流
- 即時或事後處理事件流
有些專案需要從各個應用程式中收集資料,而不同應用程式之間需要知道彼此的 API 接口才能串接。這些整合的過程會增加開發的難度,事件流過於複雜,如下圖所示:
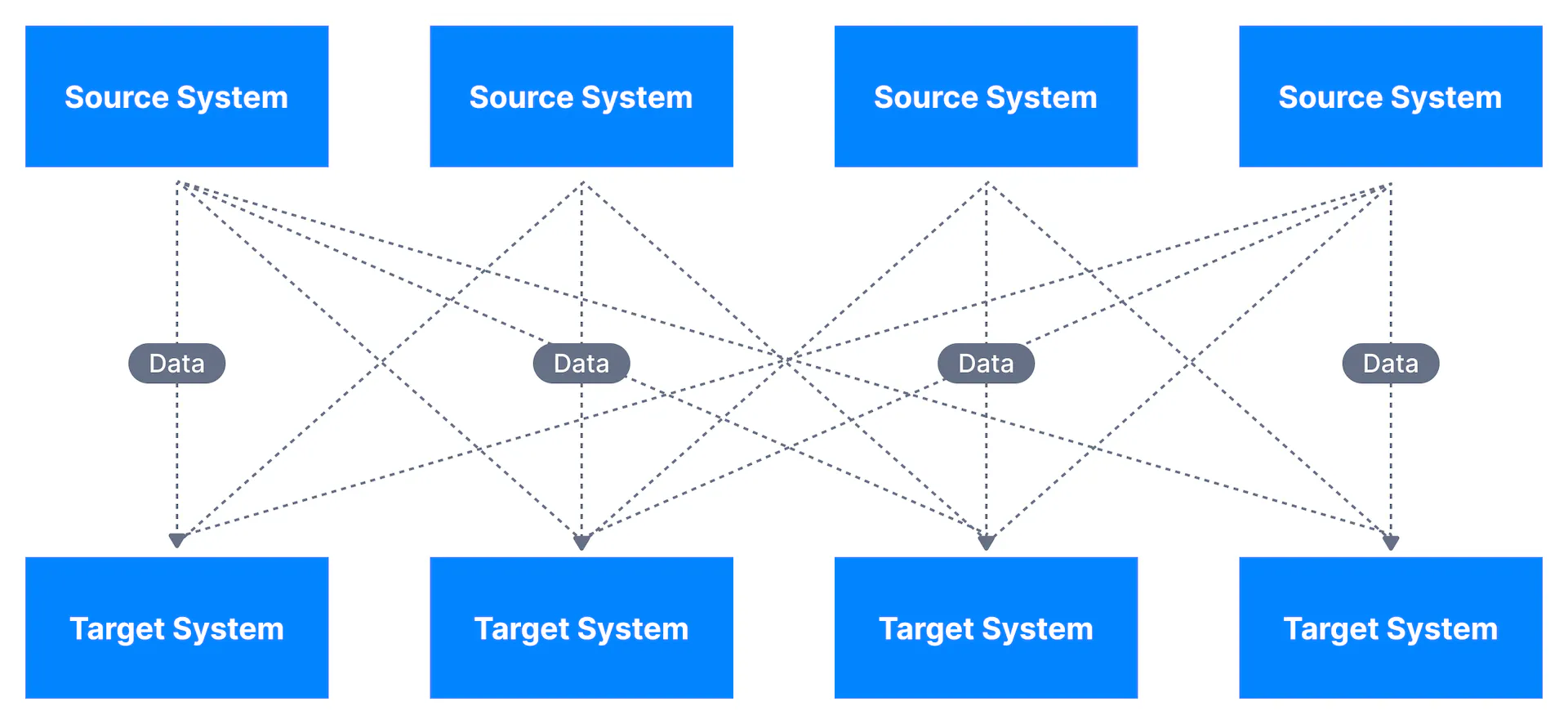
附圖來源:Conduktor
使用 Kafka 提供的發布和訂閱(pub/sub),就能降低應用程式間的耦合性,簡化資料整合的過程。
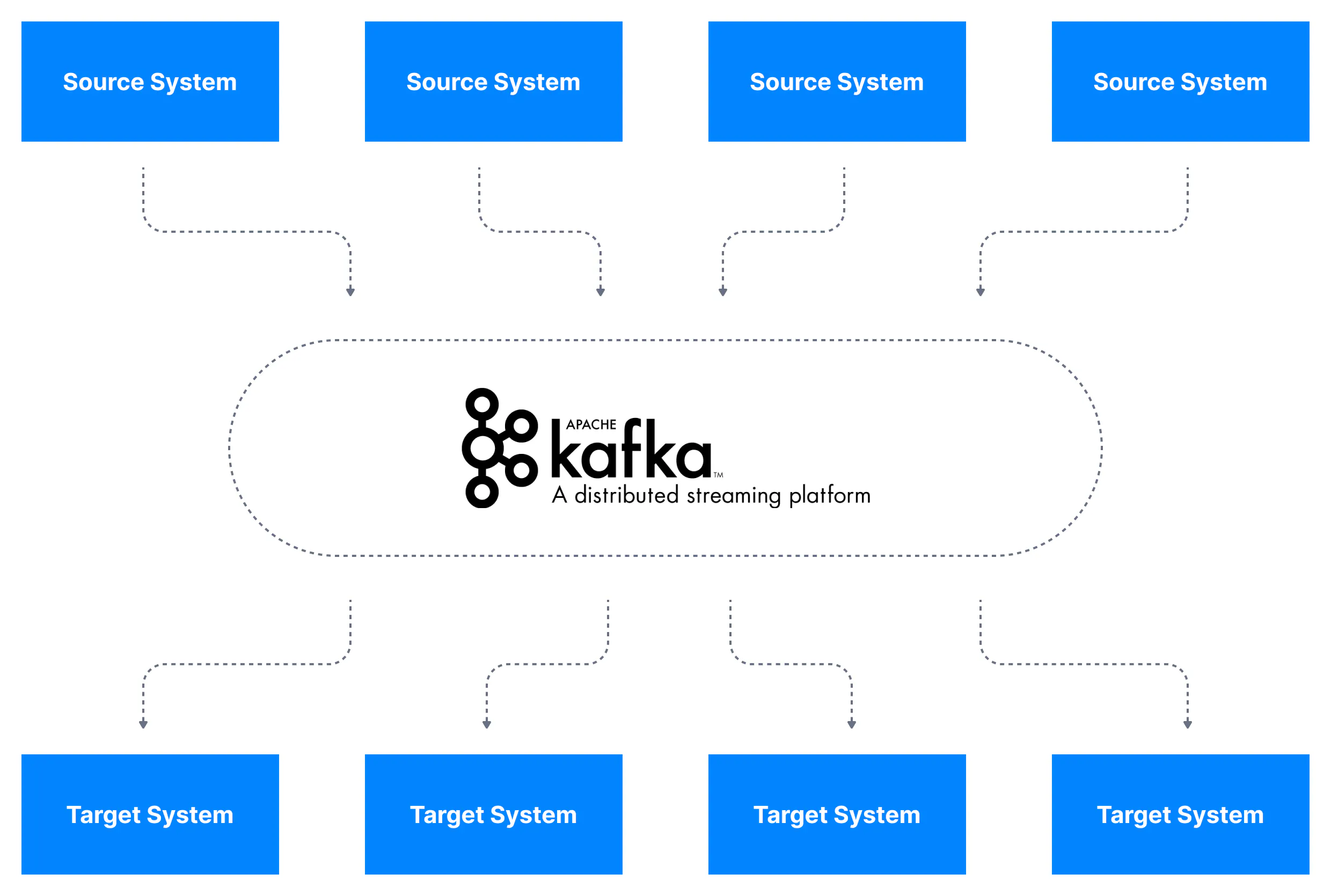
附圖來源:Conduktor
Kafka 的應用場景
前面也有提到,Kafka 是專門處理大流量的事件流。如果你的應用場景吞吐量較小、沒有太複雜的事件流,或是只需要 Message queue 功能的話,建議選擇其他工具來使用。因為部署和維護 Kafka 的成本都不低,採用前應謹慎評估。
Kafka 的架構
Kafka 術語說明
- Record(訊息):也稱作記錄,是 Kafka 中最小單位的資料,放在 Partition 中。
- Topic(主題):分類訊息,進入到 Kafka 的訊息都會被歸類到某個 Topic 之下,相當於資料庫中的 Table。每個 Topic 中會包含多個 Partition。
- Broker(主機):儲存資料的主機伺服器,可以儲存一個或多個 Partition。
- Partition(分區):每個 Topic 中的訊息會被分為若干個 Partition,以提高訊息的處理效率。同一個 Topic 下的 Partition 可以分布在不同的 Broker 中,分散機器損壞的風險。
- Producer(生產者):將訊息寫入 Topic 中的客戶端應用程序。
- Consumer(消費者): 訂閱 Topic 以接收訊息的客戶端應用程序。
- Consumer Group(消費者群組):一個或多個消費者會組成群組,以便實現訊息的並行處理,提高整體效率。
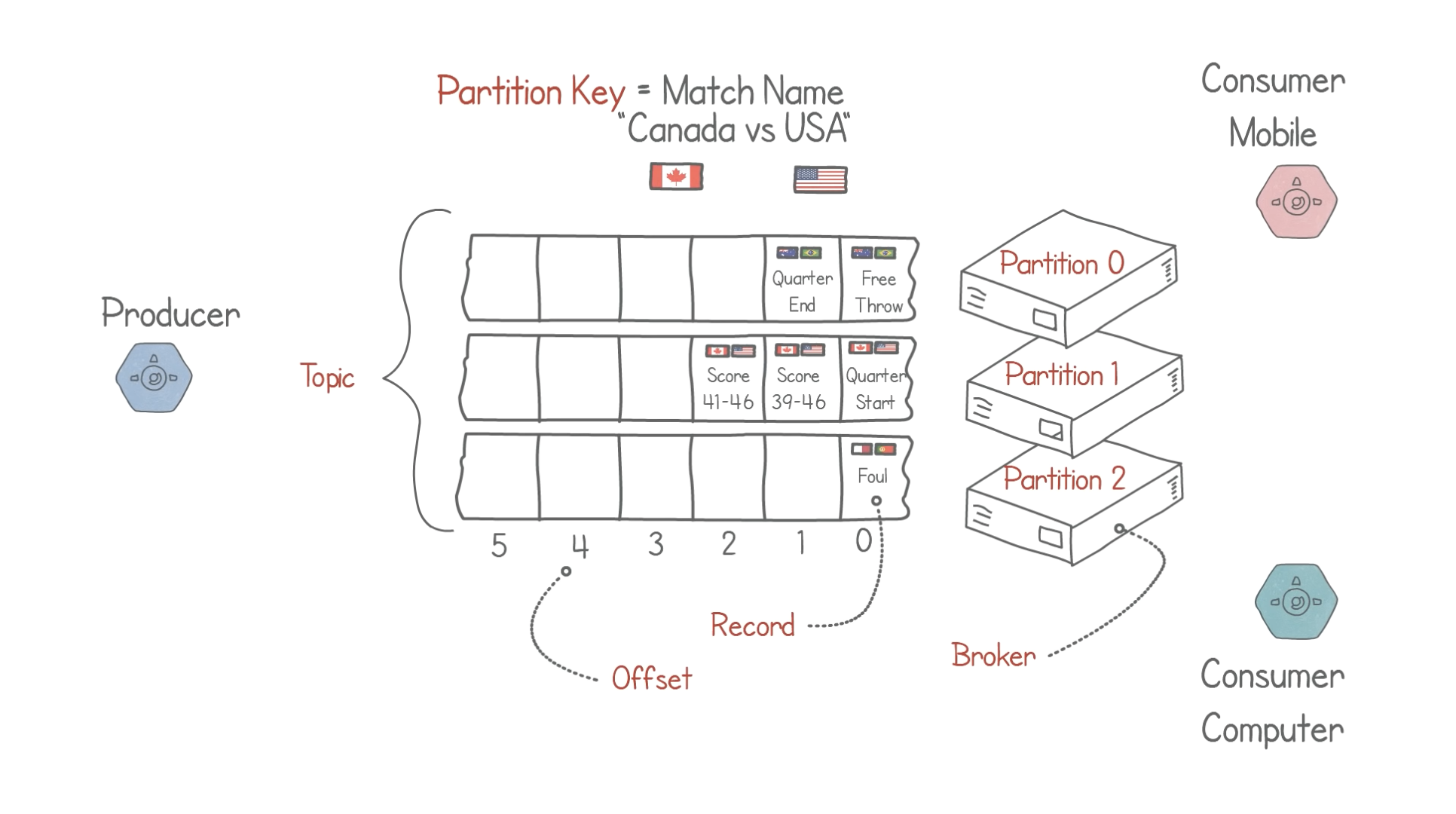
從以上這張架構圖可以看到,生產者和消費者彼此是完全解耦且互不可知的,這正是實現 Kafka 高可擴展性的關鍵元素,因為生產者永遠不須等待消費者。
Kafka 的佇列模式
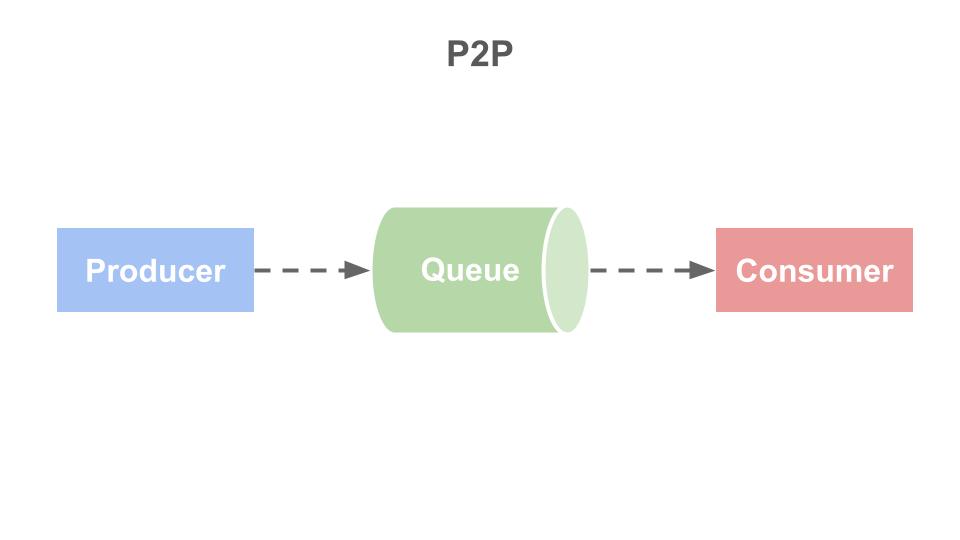
點對點模式(P2P):生產者收集的訊息儲存在 Queue 中,由一個或多個消費者進行消費,但是一個訊息只能被消費一次。當訊息被消費時就會從佇列中刪除,這樣一來即使有多個消費者同時消費,也能保證訊息處理的順序。
舉例來說:訂單處理系統讓多個訂單處理器同時工作,但一個訂單只會由一個訂單處理器來處理。
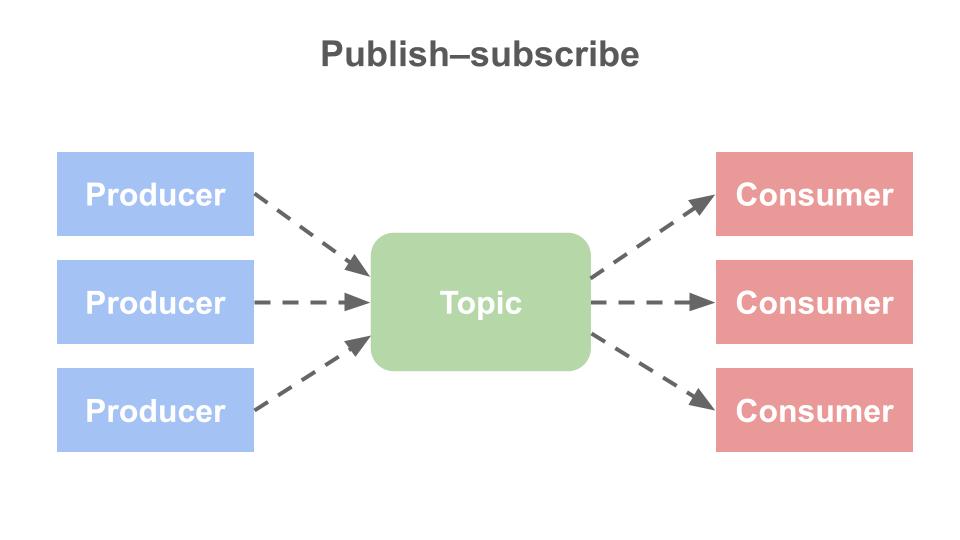
發布/訂閱(Pub/sub):各個生產者從不同來源收集來的訊息送入專屬的 Topic 中,再由消費者訂閱各自需要的 Topic,並取用資料。在發布/訂閱模式中,訊息可以被多個消費者消費。
在 Node.js 使用 Kafka
具體做法大致上如下:
- 建立 Kafka
- 建立分別用作 Producer 和 Consumer 的兩個 Node.js Apps
- 讓 Producer 發送訊息,並由 Consumer 消費
事前準備
請根據電腦的作業系統下載 Docker,這是一個可提供容器給 Kafka 使用的工具,相當於 broker。Docker 應用程式能夠在不同的環境中運行,不論是在開發、測試或生產伺服器,應用程式都能保持一致的運行方式。讓應用程式更便於打包和分享。
開啟 Docker Desktop 後,按照指示完成所有安裝步驟。然後在 CMD 檢查安裝是否完成。
$ docker -v
查看終止狀態的容器
bash
$ docker ps -a
以下步驟參考自手把手帶你建立 Node.js 專案 & Kafka 環境,透過實作了解 Kafka 的運行邏輯
步驟一:建立專案
建立 Node js 專案,並安裝 kafkajs
npm init -f
npm install --save kafkajs
步驟二:新增儲存 Kafka 數據的資料夾
在 Docker Compose 中,容器 (container) 內的數據可以永久保存在主機上。即使容器被刪除,數據仍然能夠讀取。
這裡新增的資料夾路徑會放在 docker-compose.yml裡的 volumes,它定義了容器內的目錄或文件與主機的目錄之間的映射關係。
mkdir -p deploy/kafkaCluster/kraft
步驟三:設定 docker-compose.yml
由於 Kafka 正逐步移除對 Zookeeper 的依賴,所以這裡選擇使用 KRaft 儲存資料。
version: "3"
services:
kafka:
image: "bitnami/kafka:latest"
ports:
- "9092:9092"
environment:
# 啟用 KRaft 模式
- KAFKA_ENABLE_KRAFT=yes
# 設置 KRaft 監聽器的相關參數,例如端口和地址
- KAFKA_CFG_PROCESS_ROLES=broker,controller
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://127.0.0.1:9092
# 確保每個 Kafka 節點都有一個唯一的節點 ID
- KAFKA_CFG_NODE_ID=1
- KAFKA_BROKER_ID=1
- [email protected]:9093
# 啟用 PLAINTEXT 監聽器
- ALLOW_PLAINTEXT_LISTENER=yes
volumes:
# 設定資料的儲存位置
- ./deploy/kafkaCluster/kraft:/bitnami/kafka:rw
步驟四:執行 Docker
透過以下指令,讓 Docker Compose 根據配置文件啟動應用程序的所有容器。
docker-compose up -d
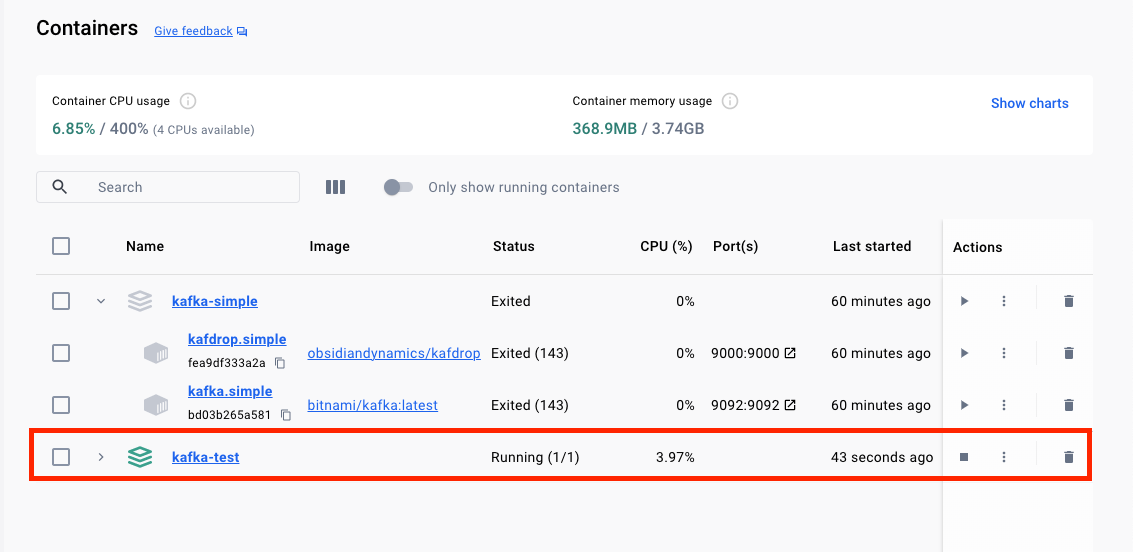
如下圖,kafka-test 為啟動的狀態:
步驟五:建立生產者
在這個 Node.js 程式中,我們首先創建了一個 AdminClient 對象,用於執行 Kafka 的管理操作。使用其中的 createTopics 方法來創建新的 Topic。在建立 Topic 時,可以指定 Topic 名稱、Partitions 數量以及副本數量等參數。
有了 Topic 後,才能讓 Producer 發送訊息。
(以下程式碼使用 ChatGPT 生成)
// producer.js
const { Kafka } = require("kafkajs");
const kafka = new Kafka({
clientId: "my-producer",
brokers: ["localhost:9092"], // 請根據實際情況更換 Kafka Broker 地址
});
const admin = kafka.admin();
// 定義 topic, 分區數量, 副本數量
const topic = "topic-for-test";
const numPartitions = 3;
const replicationFactor = 1;
// 創建 topic
async function createTopic() {
try {
await admin.connect();
await admin.createTopics({
topics: [
{
topic: topic, // 主題名稱
numPartitions: numPartitions, // 分區數量
replicationFactor: replicationFactor, // 副本數量
},
],
});
console.log(`Topic ${topic} created successfully!`);
} catch (error) {
console.error("Error creating topic:", error);
} finally {
await admin.disconnect();
}
}
createTopic();
// 創建一個生產者實例
const producer = kafka.producer();
// 定義要發送的消息
const message = {
key: "test-key",
value: "Hello Kafka!",
};
// 定義發送消息的函數
const produceMessage = async () => {
try {
// 連接到 Kafka Broker
await producer.connect();
// 發送消息
await producer.send({
topic,
messages: [message],
});
console.log("Message sent successfully!");
} catch (error) {
console.error("Error producing message:", error);
} finally {
// 關閉生產者
await producer.disconnect();
}
};
// 執行發送消息的函數
produceMessage();
步驟六:建立消費者
// consumer.js
const { Kafka } = require("kafkajs");
const kafka = new Kafka({
clientId: "my-consumer",
brokers: ["localhost:9092"], // 請根據實際情況更換為你的 Kafka Broker 地址
});
// 創建一個消費者實例
const consumer = kafka.consumer({ groupId: "test-group" });
// 訂閱主題
const topic = "topic-for-test";
// 定義處理消息的函數
const processMessage = async () => {
try {
// 連接到 Kafka Broker
await consumer.connect();
// 訂閱主題
await consumer.subscribe({ topic, fromBeginning: true });
// 監聽消息
await consumer.run({
eachMessage: async ({ topic, partition, message }) => {
console.log({
value: message.value.toString(), // 將消息值轉換為字符串
});
},
});
} catch (error) {
console.error("Error consuming message:", error);
}
};
// 執行消費消息的函數
processMessage();
步驟七:執行專案
執行以下指令,讓 Producer 傳送訊息。
建議可以把終端機分割成兩塊,比較方便看到 Kafka 運作的流程。
node producer.js
在另一個終端執行,讓 Consumer 接收訊息。
node consumer.js
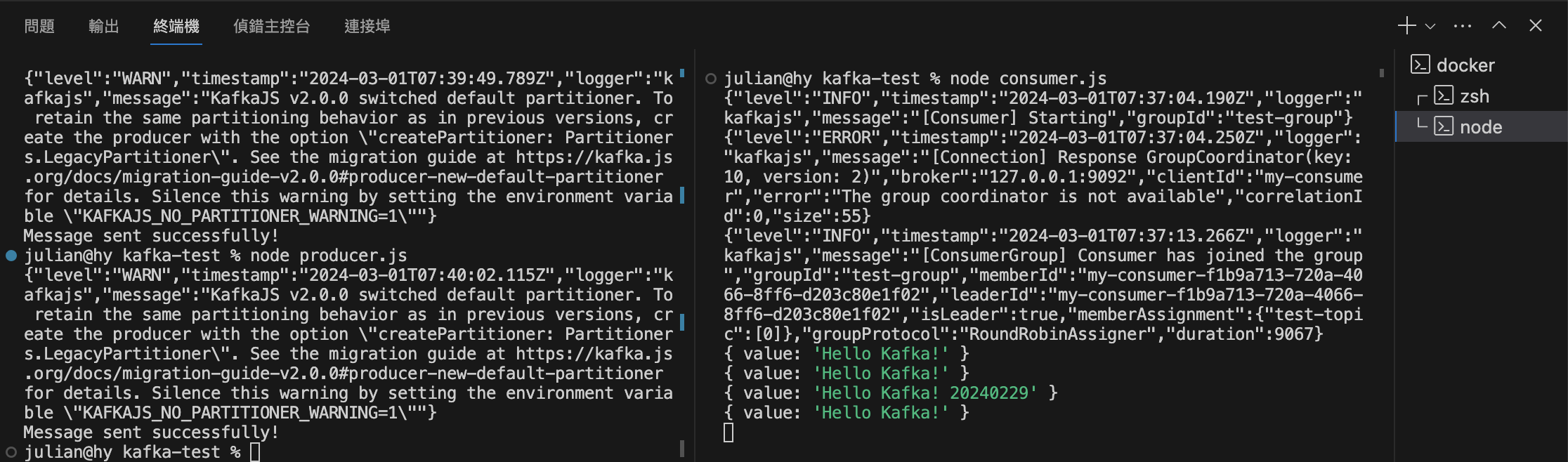 結果應該如上,左邊為 Producer ,右邊為 Consumer。
結果應該如上,左邊為 Producer ,右邊為 Consumer。
可以看到 Consumer 有確實接收到訊息。
Kafka 效能檢測
測試內容如下:
- Produce 多筆資料到 topic,記錄所花費的時間
- Consume topic 中的所有訊息,記錄所花費的時間
- 計算資料丟失率
根據實驗結果,得到以下結論:
- Kafka 的 Produce TPS 約為 `每秒 302.52 次`
- Kafka 的 Consume 10 萬筆的 TPS 約為 `每秒 869565.22 次`
- Kafka 在 10 萬筆以下的資料丟失率為 `0%`
實驗結果
Produce
| 一千筆 | 一萬筆 | 十萬筆 |
|---|---|---|
| 3,326 ms | 34,341 ms | 328,590 ms |
Consume
| 一千筆 | 一萬筆 | 十萬筆 |
|---|---|---|
| 101 ms | 102 ms | 115 ms |
Data Loss Percentage
| 一千筆 | 一萬筆 | 十萬筆 |
|---|---|---|
| 0% | 0% | 0% |
